
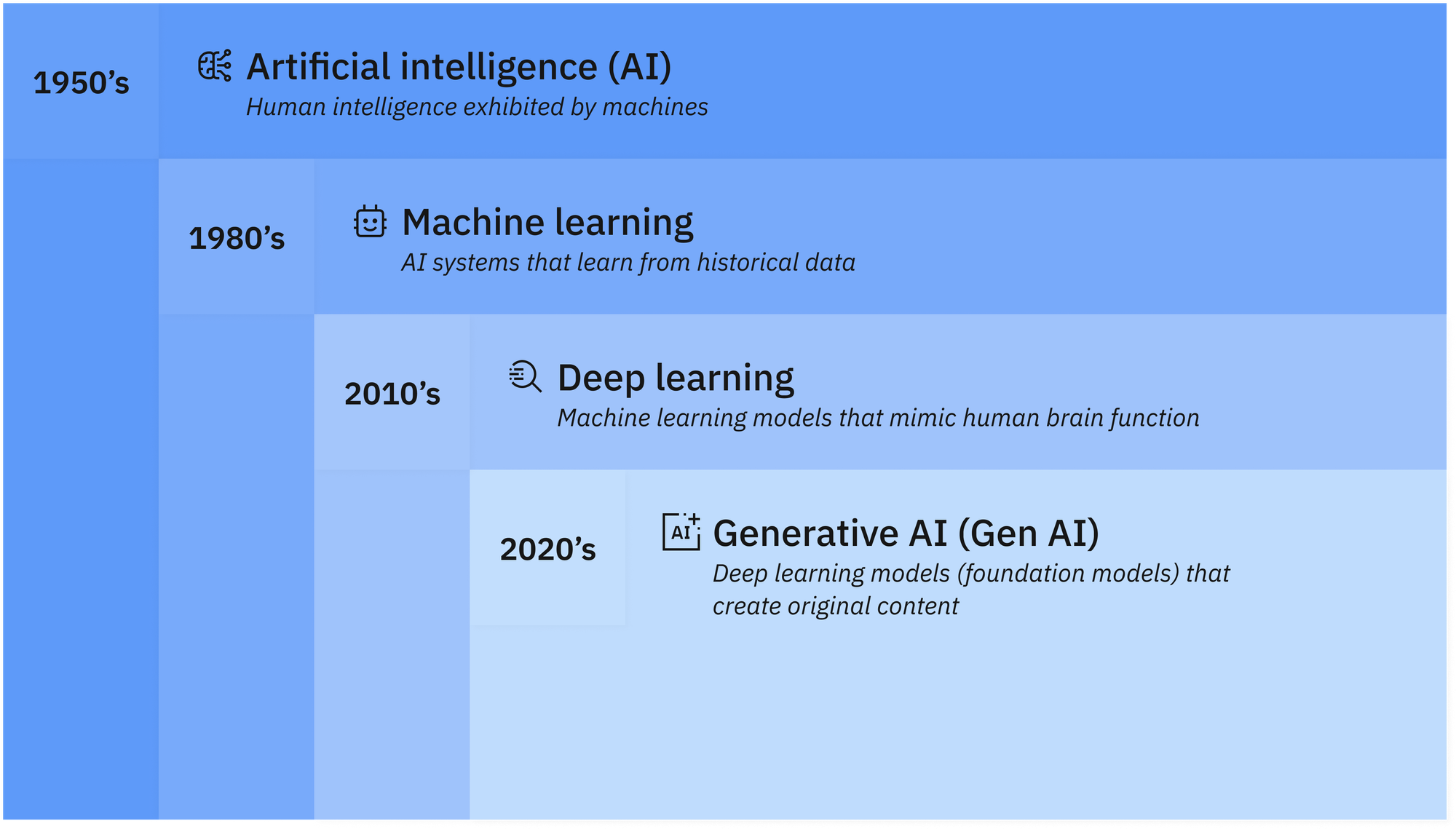
هوش مصنوعی (Artificial Intelligence) چیست؟

هوش مصنوعی (AI) به فناوریای گفته میشود که به کامپیوترها و ماشینها امکان میدهد تواناییهایی مانند یادگیری، درک، حل مسئله، تصمیمگیری، خلاقیت و خودمختاری را شبیهسازی کنند.
برنامهها و دستگاههای مجهز به هوش مصنوعی قادرند اشیا را تشخیص دهند، زبان انسان را درک کرده و به آن پاسخ دهند، از اطلاعات جدید بیاموزند و توصیههای دقیق ارائه دهند. همچنین میتوانند بهصورت مستقل عمل کنند و در برخی موارد جایگزین هوش انسانی شوند؛ مانند خودروهای خودران که بدون نیاز به راننده حرکت میکنند.
با این حال، در سال ۲۰۲۴ تمرکز اصلی پژوهشگران و متخصصان هوش مصنوعی، و همچنین تیترهای خبری، بر روی هوش مصنوعی مولّد (Generative AI) است. این فناوری قادر است متون، تصاویر، ویدیوها و سایر محتوای اصیل و جدید تولید کند. برای درک بهتر هوش مصنوعی مولد، ابتدا باید با مفاهیم پایهای آن، یعنی یادگیری ماشین و یادگیری عمیق، آشنا شد.
یادگیری ماشین (Machine Learning)
یکی از سادهترین روشها برای درک هوش مصنوعی، بررسی آن بهعنوان مجموعهای از مفاهیم در همتنیده است که طی بیش از ۷۰ سال تکامل یافتهاند.
در این میان، یادگیری ماشین (ML) یکی از شاخههای اصلی هوش مصنوعی است که با استفاده از دادهها، مدلهایی را آموزش میدهد تا بتوانند الگوها را تشخیص داده و پیشبینیهایی انجام دهند. در واقع، یادگیری ماشین به کامپیوترها امکان میدهد بدون برنامهنویسی مستقیم، از دادهها بیاموزند و تصمیمگیری کنند.
الگوریتمهای متعددی در یادگیری ماشین بهکار گرفته میشوند که هر یک برای حل مسائل خاصی طراحی شدهاند. برخی از رایجترین آنها عبارتاند از:
- رگرسیون خطی و لجستیک
- درختهای تصمیمگیری
- جنگل تصادفی
- ماشینهای بردار پشتیبان (SVM)
- نزدیکترین همسایه (KNN)
- خوشهبندی و سایر روشها
یکی از قدرتمندترین روشهای یادگیری ماشین، شبکههای عصبی مصنوعی هستند. این شبکهها از ساختار و عملکرد مغز انسان الهام گرفته شدهاند و شامل لایههایی از گرهها (نورونها) هستند که برای تحلیل دادههای پیچیده بهکار میروند.
یکی از سادهترین و متداولترین روشهای یادگیری ماشین، یادگیری نظارتشده است. در این روش، مدل با استفاده از مجموعهای از دادههای دارای برچسب آموزش میبیند تا بتواند اطلاعات جدید را دستهبندی کند یا پیشبینیهای دقیقی ارائه دهد.
یادگیری عمیق (Deep Learning)
یادگیری عمیق زیرمجموعهای از یادگیری ماشین است که بر پایه شبکههای عصبی چندلایه (شبکههای عصبی عمیق) عمل میکند و ساختاری شبیه به مغز انسان دارد.
ویژگی اصلی شبکههای عصبی عمیق، وجود لایههای متعدد پردازشی است. برخلاف شبکههای عصبی معمولی که اغلب یک یا دو لایه مخفی دارند، در یادگیری عمیق حداقل سه لایه مخفی (و معمولاً صدها لایه) وجود دارد. این لایههای اضافی امکان یادگیری ویژگیهای پیچیدهتر را فراهم میکنند.
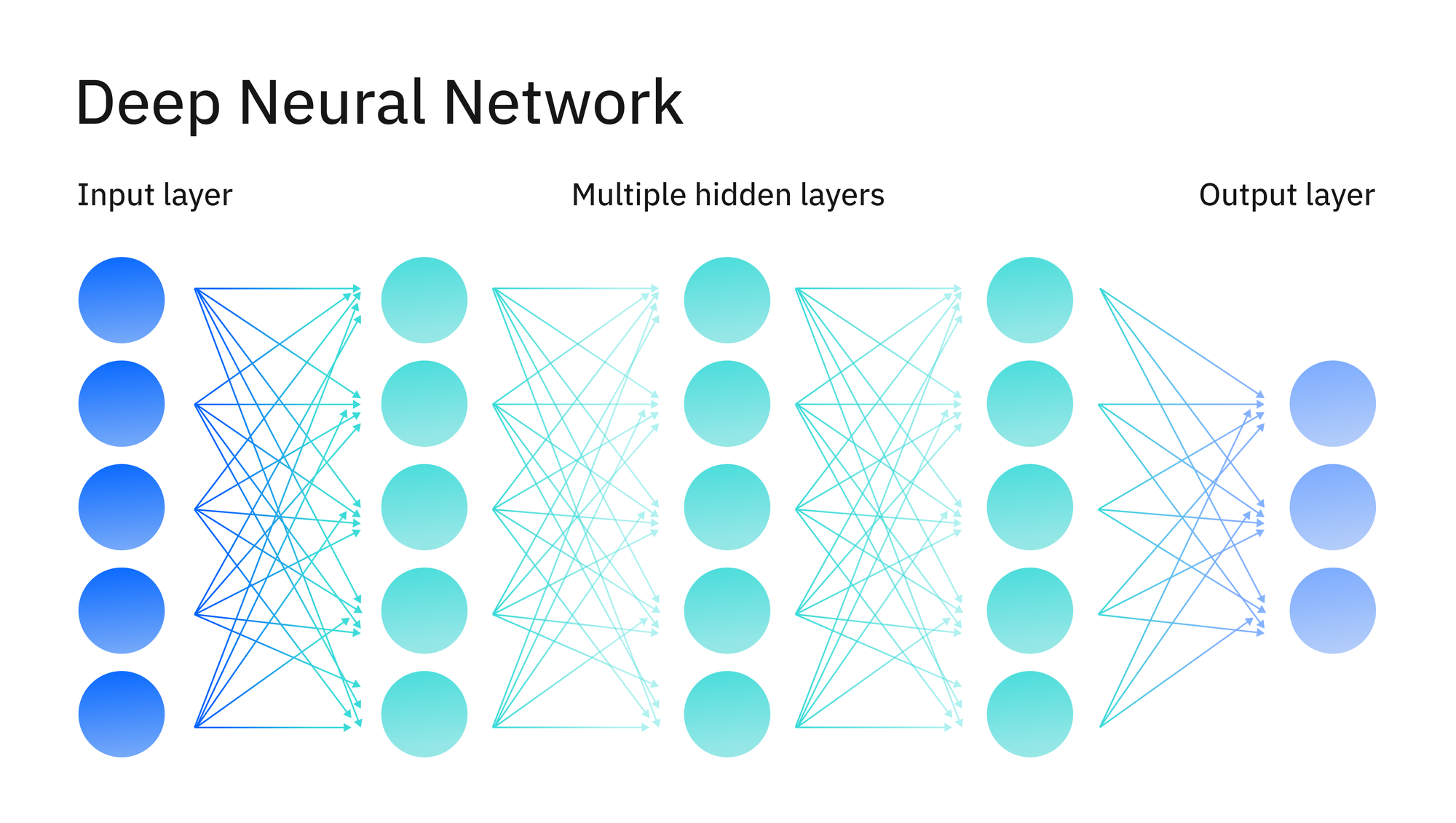
یادگیری عمیق میتواند بدون نظارت انسانی از حجم عظیمی از دادههای بدون برچسب یاد بگیرد. این ویژگی آن را برای کاربردهایی مانند پردازش زبان طبیعی (NLP)، بینایی کامپیوتری و تحلیل دادههای پیچیده بسیار مناسب کرده است.
روشهای یادگیری مبتنی بر یادگیری عمیق شامل موارد زیر است:
- یادگیری نیمهنظارتشده: ترکیبی از یادگیری نظارتشده و بدون نظارت، که از دادههای دارای برچسب و بدون برچسب برای آموزش مدل استفاده میکند.
- یادگیری خودنظارتی: مدلی که بهجای استفاده از دادههای برچسبگذاریشده، از ویژگیهای ذاتی دادهها برای یادگیری بهره میبرد.
- یادگیری تقویتی: مدلی که با آزمون و خطا و بر اساس سیستم پاداش یاد میگیرد.
- یادگیری انتقالی: استفاده از دانشی که مدل در یک حوزه آموخته است، برای بهبود عملکرد آن در یک حوزه مرتبط دیگر.
هوش مصنوعی مولد (Generative AI)
هوش مصنوعی مولد (Generative AI) یکی از مهمترین دستاوردهای یادگیری عمیق است که توانایی تولید محتوای جدید را دارد. این فناوری میتواند متن، تصویر، ویدیو، صدا و سایر محتواهای دیجیتال را از ابتدا تولید کند.
مدلهای مولد، دادههای آموزشی خود را به یک نمایش فشرده تبدیل میکنند و سپس از این دانش برای تولید محتوای جدیدی استفاده میکنند که مشابه دادههای اصلی است، اما کاملاً یکسان با آنها نیست.
در سالهای اخیر، مدلهای مولد پیشرفت زیادی کردهاند و سه فناوری کلیدی در این حوزه معرفی شدهاند:
- رمزگذارهای خودبازگشتی متغیر (VAEs) – این مدلها که در سال ۲۰۱۳ معرفی شدند، امکان ایجاد نسخههای مختلفی از یک محتوا را در پاسخ به یک درخواست فراهم کردند.
- مدلهای انتشار (Diffusion Models) – این مدلها که در سال ۲۰۱۴ ظهور یافتند، با اضافه کردن نویز به تصاویر و سپس حذف تدریجی آن، میتوانند تصاویر جدید و واقعی تولید کنند.
- مدلهای ترنسفورمر (Transformers) – این مدلها توانایی پردازش و تولید محتوای متوالی مانند جملات در یک متن، فریمهای یک ویدیو یا کدهای برنامهنویسی را دارند.
ترنسفورمرها اکنون در قلب بسیاری از ابزارهای پیشرفته هوش مصنوعی مولد قرار دارند، از جمله:
- ChatGPT و GPT-4
- Copilot
- BERT
- Bard
- Midjourney
هوش مصنوعی مولد یکی از نوآورانهترین شاخههای هوش مصنوعی است که با پیشرفت آن، شاهد تحول در تولید محتوا، طراحی گرافیکی، کدنویسی و حتی علوم پزشکی خواهیم بود.
هوش مصنوعی مولد چگونه کار میکند؟
بهطور کلی، هوش مصنوعی مولد در سه مرحله عمل میکند:
- آموزش برای ایجاد یک مدل پایه.
- تنظیم و بهینهسازی برای سازگاری مدل با یک کاربرد خاص.
- تولید، ارزیابی و تنظیم بیشتر برای بهبود دقت و عملکرد.
مرحله اول: آموزش
هوش مصنوعی مولد با یک مدل پایه آغاز میشود؛ این مدل یک شبکه عصبی عمیق است که بهعنوان زیربنای انواع برنامههای مولد عمل میکند.
امروزه رایجترین مدلهای پایه، مدلهای زبانی بزرگ (LLMs) هستند که برای تولید متن بهکار میروند. اما مدلهای پایهای دیگری نیز برای تولید تصویر، ویدیو، صدا و موسیقی وجود دارند. همچنین، مدلهای چندوجهی قادرند انواع مختلفی از محتوا را پشتیبانی کنند.
برای ایجاد یک مدل پایه، الگوریتمهای یادگیری عمیق روی حجم عظیمی از دادههای خام، بدون ساختار و بدون برچسب آموزش میبینند. این دادهها میتوانند ترابایتها یا پتابایتها از متن، تصویر یا ویدیو باشند که از اینترنت جمعآوری شدهاند.
نتیجهی این فرایند، یک شبکه عصبی با میلیاردها پارامتر است که میتواند بهطور مستقل و در پاسخ به درخواستها، محتوا تولید کند. این مدل پایه بسیار پرهزینه و زمانبر است و نیاز به هزاران واحد پردازش گرافیکی (GPU) و هفتهها پردازش دارد که معمولاً میلیونها دلار هزینه در بر دارد. پروژههای متنباز مانند Llama-2 متا به توسعهدهندگان امکان میدهند تا از این مرحله پرهزینه صرفنظر کنند.
مرحله دوم: تنظیم و بهینهسازی مدل
پس از آموزش مدل پایه، لازم است که مدل برای یک کاربرد خاص تنظیم و بهینهسازی شود. این کار به روشهای مختلفی انجام میشود، از جمله:
- تنظیم دقیق (Fine-Tuning): شامل تغذیهی مدل با دادههای برچسبگذاریشدهی مربوط به کاربرد مشخص، مانند مجموعهای از سوالات و پاسخهای صحیح در یک قالب خاص.
- یادگیری تقویتی با بازخورد انسانی (RLHF): در این روش، کاربران انسانی خروجیهای مدل را ارزیابی کرده و اصلاحات لازم را اعمال میکنند تا مدل عملکرد بهتری داشته باشد. این فرایند میتواند از طریق تصحیح پاسخهای یک چتبات یا بازخورد کاربران انجام شود.
مرحله سوم: تولید، ارزیابی و بهینهسازی مداوم
پس از تنظیم اولیه، توسعهدهندگان و کاربران بهطور منظم خروجیهای مدل را ارزیابی میکنند و برای افزایش دقت و تطبیق بهتر، مدل را دوباره تنظیم میکنند. در برخی موارد، این تنظیمات بهصورت هفتگی انجام میشود، در حالی که مدلهای پایه معمولاً هر یک تا دو سال بهروزرسانی میشوند.
یکی دیگر از روشهای بهینهسازی، تولید تقویتشده با بازیابی (RAG) است. این روش به مدل اجازه میدهد تا از منابع خارجی فراتر از دادههای آموزشی اولیه استفاده کند تا دقت و ارتباط محتوای تولیدی را افزایش دهد.
مزایای هوش مصنوعی
هوش مصنوعی کاربردهای گستردهای در صنایع مختلف دارد. برخی از مهمترین مزایای آن عبارتاند از:
✅ اتوماسیون وظایف تکراری
✅ بینش سریعتر و دقیقتر از دادهها
✅ تصمیمگیری بهینه و کارآمد
✅ کاهش خطای انسانی
✅ دسترسی ۲۴/۷ بدون وقفه
✅ کاهش خطرات فیزیکی برای انسان
۱. اتوماسیون وظایف تکراری
هوش مصنوعی میتواند وظایف یکنواخت و تکراری را، چه دیجیتالی (مانند پردازش دادهها) و چه فیزیکی (مانند بستهبندی در انبارها)، خودکار کند. این امر باعث میشود نیروی انسانی روی کارهای خلاقانه و ارزشمندتر متمرکز شود.
۲. بهبود تصمیمگیری
هوش مصنوعی میتواند تصمیمگیری را سریعتر، دقیقتر و مبتنی بر دادهها کند. این ویژگی به کسبوکارها امکان میدهد تا به فرصتها واکنش سریع نشان دهند و بحرانها را در لحظه مدیریت کنند.
۳. کاهش خطای انسانی
از کمک به جراحیهای دقیق پزشکی گرفته تا پیشگیری از اشتباهات مالی در بانکداری، هوش مصنوعی میتواند احتمال بروز خطا را به حداقل برساند.
۴. در دسترس بودن ۲۴/۷
چتباتهای مبتنی بر هوش مصنوعی و دستیارهای مجازی میتوانند بدون نیاز به نیروی انسانی، بهصورت شبانهروزی خدمات ارائه دهند. این قابلیت در صنایع مانند پشتیبانی مشتریان و تولید محتوا بسیار سودمند است.
۵. کاهش خطرات فیزیکی
هوش مصنوعی میتواند انجام وظایف خطرناک مانند کار در اعماق دریا، ارتفاعات بالا، فضا و حتی خنثیسازی بمب را بر عهده بگیرد و ایمنی کارکنان را افزایش دهد.
کاربردهای هوش مصنوعی
برخی از کاربردهای رایج هوش مصنوعی در صنایع مختلف شامل موارد زیر است:
- پشتیبانی مشتریان: چتباتها و دستیارهای مجازی برای پاسخگویی سریع و شبانهروزی.
- تشخیص تقلب: شناسایی الگوهای مشکوک در تراکنشهای مالی با استفاده از یادگیری ماشین.
- بازاریابی شخصیسازیشده: ارائه پیشنهادهای خرید بر اساس تحلیل دادههای رفتاری مشتریان.
- استخدام و منابع انسانی: غربالگری رزومهها و مصاحبههای اولیه با کمک الگوریتمهای هوش مصنوعی.
- توسعه نرمافزار: استفاده از ابزارهای هوش مصنوعی برای تولید و بهینهسازی کد.
- نگهداری پیشبینانه: پیشبینی خرابی تجهیزات در کارخانهها با استفاده از تحلیل دادههای حسگرها.
چالشها و ریسکهای هوش مصنوعی
با وجود مزایای بیشمار، پیادهسازی هوش مصنوعی با چالشهایی همراه است:
🚨 ریسکهای دادهای: احتمال نشت داده، دستکاری اطلاعات یا سوگیری دادهها.
🚨 ریسکهای مدل: خطر سرقت، مهندسی معکوس یا تغییرات غیرمجاز در مدل.
🚨 ریسکهای عملیاتی: مشکلاتی مانند کاهش عملکرد مدل، سوگیری و آسیبپذیریهای امنیتی.
🚨 ریسکهای اخلاقی و قانونی: امکان نقض حریم خصوصی و تولید نتایج تبعیضآمیز.
نتیجهگیری: هوش مصنوعی مولد یکی از انقلابیترین پیشرفتها در فناوری است که در حال تغییر نحوه تولید محتوا، تصمیمگیری و تعامل با دادهها است. با این حال، برای بهرهمندی از تمامی مزایای آن، باید مدیریت ریسک و مسئولیتپذیری اخلاقی را در اولویت قرار داد.
اخلاق و حاکمیت هوش مصنوعی
اخلاق هوش مصنوعی یک حوزه چندرشتهای است که به بررسی چگونگی بهینهسازی تأثیرات مثبت هوش مصنوعی و در عین حال کاهش ریسکها و پیامدهای نامطلوب آن میپردازد. اصول اخلاقی هوش مصنوعی از طریق سیستمی از حاکمیت هوش مصنوعی اجرا میشوند که شامل تدابیری برای اطمینان از ایمنی و اخلاقی بودن ابزارها و سیستمهای هوش مصنوعی است.
حاکمیت هوش مصنوعی شامل سازوکارهای نظارتی برای رسیدگی به ریسکها میشود. یک رویکرد اخلاقی به حاکمیت هوش مصنوعی مستلزم مشارکت طیف گستردهای از ذینفعان، از جمله توسعهدهندگان، کاربران، سیاستگذاران و متخصصان اخلاق است تا اطمینان حاصل شود که سیستمهای مرتبط با هوش مصنوعی مطابق با ارزشهای جامعه توسعه یافته و مورد استفاده قرار میگیرند.
ارزشهای اصلی در اخلاق و مسئولیتپذیری هوش مصنوعی:
قابلیت توضیح و تفسیر
با پیشرفت هوش مصنوعی، درک و ردیابی نحوه دستیابی الگوریتم به یک نتیجه برای انسانها دشوارتر میشود. هوش مصنوعی قابل توضیح مجموعهای از فرآیندها و روشهایی است که به کاربران انسانی اجازه میدهد نتایج و خروجیهای ایجاد شده توسط الگوریتمها را تفسیر کرده، درک نموده و به آنها اعتماد کنند.
عدالت و شمولپذیری
یادگیری ماشین ذاتاً نوعی تبعیض آماری است، اما این تبعیض زمانی غیرقابل قبول میشود که بهطور سیستماتیک گروههای خاصی را در موقعیت برتری قرار دهد و گروههای دیگر را در معرض نابرابری قرار دهد، که میتواند منجر به آسیبهای مختلفی شود. برای تشویق عدالت، متخصصان میتوانند با کاهش سوگیری الگوریتمی در جمعآوری دادهها و طراحی مدل، و همچنین ایجاد تیمهای متنوع و فراگیر، این مشکل را کاهش دهند.
استحکام و امنیت
یک سیستم هوش مصنوعی قوی قادر است شرایط استثنایی مانند ورودیهای غیرعادی یا حملات مخرب را بدون ایجاد آسیب ناخواسته مدیریت کند. همچنین، چنین سیستمی در برابر مداخلات عمدی و غیرعمدی مقاوم است و از آسیبپذیریهای آشکار محافظت میکند.
پاسخگویی و شفافیت
سازمانها باید مسئولیتهای مشخص و ساختارهای حاکمیتی شفافی را برای توسعه، استقرار و نتایج سیستمهای هوش مصنوعی اجرا کنند. علاوه بر این، کاربران باید بتوانند نحوه عملکرد یک سرویس هوش مصنوعی را مشاهده کرده، قابلیتهای آن را ارزیابی نموده و نقاط قوت و محدودیتهای آن را درک کنند. افزایش شفافیت به مصرفکنندگان هوش مصنوعی این امکان را میدهد که اطلاعات بیشتری درباره نحوه ایجاد مدل یا سرویس هوش مصنوعی داشته باشند.
حریم خصوصی و تطابق با مقررات
بسیاری از چارچوبهای قانونی، از جمله GDPR، سازمانها را ملزم میکنند که هنگام پردازش اطلاعات شخصی، از اصول خاصی در زمینه حریم خصوصی پیروی کنند. محافظت از مدلهای هوش مصنوعی که ممکن است شامل اطلاعات شخصی باشند، کنترل دادههای ورودی به مدل و ایجاد سیستمهایی که بتوانند با تغییرات قوانین و نگرشهای مربوط به اخلاق هوش مصنوعی سازگار شوند، از اهمیت بالایی برخوردار است.
هوش مصنوعی ضعیف در برابر هوش مصنوعی قوی
برای درک بهتر سطوح مختلف پیچیدگی و تواناییهای هوش مصنوعی، پژوهشگران انواع مختلفی از هوش مصنوعی را بر اساس سطح پیشرفت آن تعریف کردهاند:
- هوش مصنوعی ضعیف: که به عنوان «هوش مصنوعی محدود» نیز شناخته میشود، شامل سیستمهایی است که برای انجام یک یا چند وظیفه خاص طراحی شدهاند. نمونههایی از آن شامل دستیارهای صوتی هوشمند مانند الکسا (Amazon Alexa)، سیری (Apple Siri)، چتباتهای شبکههای اجتماعی یا وسایل نقلیه خودران تسلا هستند.
- هوش مصنوعی قوی: که به عنوان «هوش مصنوعی عمومی» (AGI) نیز شناخته میشود، توانایی درک، یادگیری و بهکارگیری دانش در طیف وسیعی از وظایف را در سطحی برابر یا فراتر از هوش انسانی دارد. این سطح از هوش مصنوعی در حال حاضر نظری است و هیچ سیستم شناختهشدهای به این سطح نرسیده است. پژوهشگران بر این باورند که در صورت امکانپذیر بودن AGI، نیازمند افزایش چشمگیری در قدرت محاسباتی خواهد بود. با وجود پیشرفتهای اخیر در توسعه هوش مصنوعی، سیستمهای خودآگاهی که در داستانهای علمی-تخیلی نمایش داده میشوند، همچنان در حوزه تخیل باقی ماندهاند.
تاریخچه هوش مصنوعی
ایدهی «یک ماشین که میاندیشد» به یونان باستان بازمیگردد، اما از زمان ظهور رایانش الکترونیکی، برخی رویدادها و دستاوردهای مهم در تکامل هوش مصنوعی شامل موارد زیر هستند:
- 1950: آلن تورینگ مقاله «ماشینهای محاسباتی و هوش» را منتشر کرد و در آن آزمونی ارائه داد که امروزه به عنوان "آزمون تورینگ" شناخته میشود.
- 1956: جان مککارتی اصطلاح «هوش مصنوعی» را ابداع کرد و اولین کنفرانس هوش مصنوعی در کالج دارتموث برگزار شد.
- 1967: فرانک روزنبلات اولین رایانه مبتنی بر شبکه عصبی را ساخت که از طریق آزمایش و خطا یاد میگرفت.
- 1980: الگوریتمهای پسانتشار در شبکههای عصبی معرفی شدند.
- 1995: استوارت راسل و پیتر نورویگ کتاب «هوش مصنوعی: یک رویکرد مدرن» را منتشر کردند.
- 1997: رایانه دیپ بلو (Deep Blue) شرکت IBM گری کاسپاروف، قهرمان شطرنج جهان را شکست داد.
- 2011: واتسون شرکت IBM قهرمانان مسابقه "جئوپاردی" را شکست داد.
- 2015: رایانه مینوا (Minwa) شرکت بایدو با استفاده از شبکههای عصبی تصاویر را با دقتی بیشتر از انسان دستهبندی کرد.
- 2016: هوش مصنوعی آلفاگو (AlphaGo) شرکت دیپمایند، قهرمان جهانی بازی Go را شکست داد.
- 2022: مدلهای زبانی بزرگ (LLM) مانند ChatGPT پیشرفت چشمگیری در عملکرد هوش مصنوعی ایجاد کردند.
- 2024: مدلهای چندوجهی و مدلهای کوچکتر در هوش مصنوعی بهعنوان روندهای جدید مطرح شدند.
هوش مصنوعی همچنان در حال تحول است و انتظارات از آن در حال گسترش است. با ظهور مدلهای هوش مصنوعی چندوجهی و بهینهسازی روشهای یادگیری، آیندهی این فناوری با پیشرفتهای چشمگیر همراه خواهد بود.



